

Researchers introduced Valet: A Standardized Testbed of Traditional Imperfect-Information Card Games, a study built around 21 traditional card games to examine how AI systems handle hidden information, shifting game states, and the many ways card play reveals or conceals useful clues. The paper’s main point is simple but important: card-game AI is too often judged on isolated wins in one title, even though different games test very different forms of reasoning. AI, which is already widely used by the business world, seems to be pretty weak in this matter.
Why poker turns into a reasoning problem
Poker is where the problem becomes easiest to see. On paper, the rules are compact. In practice, the game keeps changing its meaning from one action to the next. A hand is never judged only by the cards you hold. It is judged by what the board suggests, what betting has already signaled, what stronger hands are still possible, and what weaker hands might still call.
However, ranking hands is only the start. If you check out the guide of the best poker hands in order, you will notice that they anchor the logic of the whole game, yet they do not remove the need for inference. A flush or full house is powerful, but AI cannot treat hand strength as a fixed label and stop there.

Why hand rankings are not enough for AI
It has to estimate how often such hands are possible for each player, how often they are being represented without actually being held, and how the value of a medium-strength hand shifts when the public cards narrow the possibilities. Even a very strong holding can become fragile if the visible cards make a higher combination easy to imagine.
That uncertainty spreads across every layer of play. The agent must track private information, public information, betting orders, and the simple fact that people act before the truth is visible. Teaching AI to play well, therefore, requires more than memorizing the best poker hands. It requires building a live model of hidden ranges, updating probabilities after each action, and choosing lines that still make sense against many unseen possibilities.
On top of this, here is a quiz that demonstrates poker reasoning and hand structure in practice:
https://www.instagram.com/p/DW7RE7CDGJP
What the new benchmark work changes
A useful way to read the latest research is this: the real challenge is no longer proving that AI can play one card game well, but proving that its reasoning survives when the structure of uncertainty changes.
The 2026 paper Valet pushes that idea further by building a standardized testbed of 21 traditional imperfect-information card games, spanning genres, player counts, deck structures, and different ways of hiding and revealing information.
This makes card-game AI a broader science problem
The authors also identify seven information-flow mechanisms and evaluate the suite with 200 simulations per game, split between 100 all-random runs and 100 runs with a Monte Carlo Tree Search first player. That matters because it turns “card-game AI” from a narrow showcase into a comparative science problem.

As the broader tooling landscape shows, research stacks still emphasize different kinds of difficulty. RLCard’s current environment list gives published complexity estimates for nine card environments, including no-limit Texas Hold’em at an information-set number of 10^162, while OpenSpiel’s current games catalog spans a wider mix of imperfect-information card titles such as Bridge, Hearts, Euchre, Kuhn poker, Leduc poker, Goofspiel, and Liar’s Poker.
| Research setup | Concrete scale | What it is good at |
| Valet | 21 traditional card games; 200 simulations per game | Measuring whether an AI method generalizes across different information structures |
| RLCard | 9 card environments with published complexity estimates | Stress-testing learning methods on very large single-game state spaces |
| OpenSpiel | Broad catalog including several imperfect-information card families | Comparing algorithms across many game forms under one framework |
Why big poker wins did not finish the story
The classic poker milestones still matter. In the DeepStack paper, Moravčík and colleagues called poker “the quintessential game of imperfect information,” and they backed that claim with a system that beat professional players over 44,000 hands of heads-up no-limit Texas hold ’em. That result showed that an AI could combine search, learned intuition, and belief-aware reasoning in a domain where not all facts are visible at once.
But those breakthroughs did not close the scientific question. Pluribus later showed superhuman performance in six-player no-limit Texas hold ’em, which was an even stronger sign that AI could handle multi-player bluffing and strategic balance in a major poker setting.
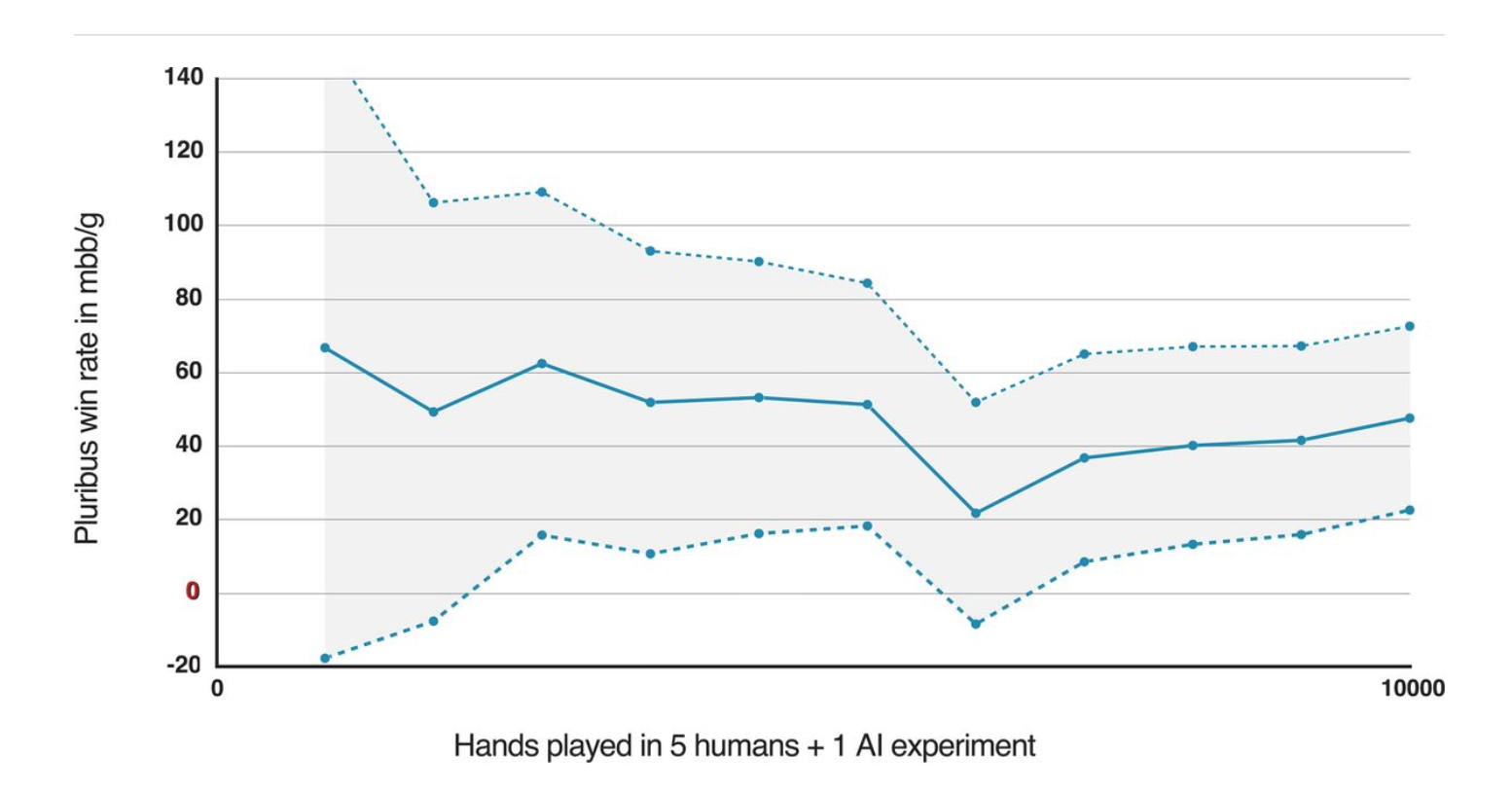
The system was not just ranking cards. It played thousands of hands against real human players, where every choice depended on hidden cards, betting patterns, and incomplete information. The chart by Science shows its win rate over time. That makes the main point clear: poker AI must handle uncertainty again and again, not just solve one hand.
Yet multiplayer poker is still only one kind of hidden-information world. Betting games reward one style of reasoning. Trick-taking games reward another. Exchange and climbing games reveal information in different rhythms. An agent that thrives in one structure may still be leaning on assumptions that quietly fail in another.

That is the deeper lesson from the newer benchmark mindset. Teaching AI to play card games is hard because the rules are precise, while the missing information keeps moving. The next real advance will be one that keeps its logic intact as the hidden information, action space, and tempo of revelation all change from game to game.



